Henry Bell, Devops Product Specialist at Google Cloud
Marcus Johansson, Devops Product Specialist at Google Cloud
Yair Weinberger, CTO at Alooma
Shani Einav, Infrastructure Lead

- Containers and Kubernetes
- GKE
- Deploying apps
- Real world implementation
1. Containers and Kubernetes

Marcus starts with a 101 intro to Containers and Kubernetes. He starts with Docker and explains the problems with running individual containers hosts in terms of scaling.
Google used Borg to orchestrate containers internally. Started work on an open source solution in 2013 which became Kubernetes. Kubernetes is built on 10 years of Google running containers internally.

Marcus explained the basics of how Kubernetes works, based on its declarative model. At the heart of Kubernetes is a reconciliation system, trying to ensure the observed state matches the declarative state.

Kubernetes is attractive because of all the things it handles for an application. For example, application health, where it will make sure your application is running if there is a failure
A big problem however is that the list of things Kubernetes handles is getting longer and longer. So people need help with it.
Kubernetes is a ‘tale of two parts’;
- Cluster Operators
- Application Developers

Cluster operators have to do a lot of things, such as updating clusters, building nodes, securing the environment etc.
2. Google Kubernetes Engine
GKE is Google’s answer to help do all of these things for cluster operators. GKE provides an SLA for the Kubernetes API. GKE has been GA since August 2015.
GKE also provides deep integration with other GCP services.
GKE master nodes are fully managed by Google and are not something a customer sees in their Google projects. All that is provided is an API endpoint.
GKE can be spun up in two ways; Zonal or Regional. Zonal is in on AZ, Regional spreads three master nodes across three Zones.
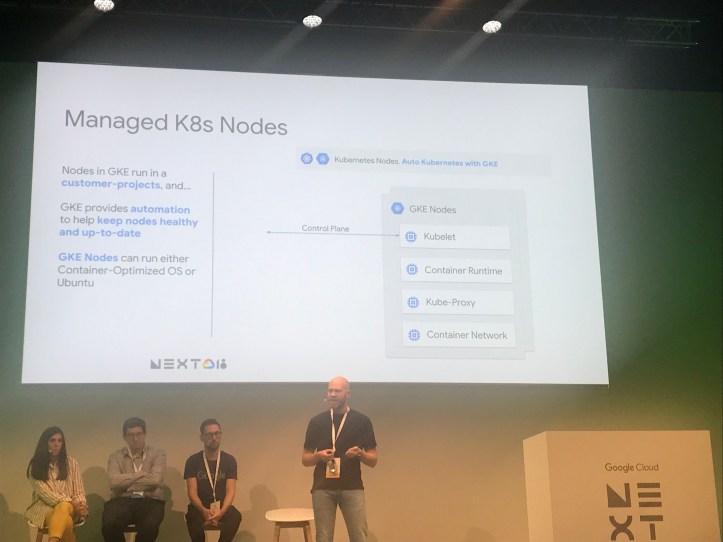
Nodes are spun up inside customer Projects. Nodes consist of the common Kubernetes worker components. The node OS either runs Google’s Container Optimised OS (COS), or Ubuntu. COS is recommended.
GKE has the concept of Node pools for providing different pools of capabilities in a cluster.
Upgrades on the master can be automatic or manually triggered. A maintenance window can be specified for scheduling updates. During an update GKE will drain traffic and then cordon that node. A new node will be spun up with the new version and the old node then removed.
GKE also supports node auto repair. If Kubernetes marks a node as NotReady, GKE will follow the same process as an update; drain,cordon,provision and remove.
3. Getting Started with Containers and Kubernetes

Henry Bell took over and moved at rapid pace through additional features and capabilities that GKE and GCP provide applications for on GKE.
Starting off with deploying containers and removing the ‘Magic’ stage between commit code and application running in production.

Skaffold helps abstract stages of deployment for developers.
How do we deploy to Production?

An example pattern is;
- Source code being committed
- Building a container
- Deploying to a registry
- Deploying to a cluster using a deployment pipeline
Spinnaker is used for this example pattern to enable deployments.
For getting traffic into a Kubernetes cluster, GKE uses by default Google’s Global Load Balancer. This provides additional capabilities such as Cloud Armor, Identity Awareness, CDN and load balancing across Kubernetes clusters.
GKE are introducing an Alpha feature called Network Endpoint Groups, to take the load off of relying on IP Tables.

GKE also supports Autoscaling to scale worker nodes automatically this is in Alpha, along with alpha support for vertical autoscaling.
HA is provided free of charge for the master if needed.
GKE also has beta of regional disks.
Stackdriver for Kubernetes is also in Beta, giving you rich and granular views of your Kubernetes clusters.
Audit logging is also in Beta in GKE.
4. Alooma Case Study

Alooma provides a data pipeline as a service. They moved from AWS to GCP. They moved from AWS to reduce costs and because costs were linear to number of customers. They realised their AWS dependency was deeper than they thought such as usage of boto3 for deployments, RDS usage, etc.

They had a number of requirements to rebuild their application and remove the linear scaling model, and this fitted containers and Kubernetes very well.

Alooma has a number of components as part of their data path, including Celery and Kafka.
They needed to move this to Kubernetes. 1) They started with stateless components. 2) Then they moved on to persistent volume claims to enable some stateful applications to be moved, such as their monitoring and logging components. 3) To enable further adoption they adopted the operator API model in Kubernetes. 4) The final step was to remove redundant components which were no longer needed on Kubernetes.
They achieved reduced costs and managed to decouple scaling the infrastructure customer growth.
And then the session wrapped up with a quick plug for Google’s Kubernetes podcast, which I also throughly recommend.
