Valentin Deleplace, Developer Advocate at Google Cloud
Andre Kelly, Product Manager for Stackdriver at Google

Valentin did a quick poll, room mostly developers but with devops folks mixed in.
There are 6 areas to consider when planning to productionise your app as a developer.
1. What are my priorities?
There are always trade offs. Top priority might be time to a demo to investors, time to launch to capture the market, saving money whilst not yet generating revenue, robustness as downtime is very costly, or other requirements.
These priorities influence questions around things like logging, high availability etc.
2. What does my load look like?
High traffic only at weekends, batch jobs overnight, high traffic during a specific time such as a launch.
This influences load and scaling, such as sizing and testing the cluster for peak load, using things like auto scaling, and scaling to zero if using serverless,
3. What skills do I have?
There may be a mismatch between the requirements and available capabilities. There may also be restrictions on what is supported by your platform.
4. What is the happy path?
What is the most critical use case on my website? For retail this is the path for a customer buying something. For Social Media this is to interact with a friend.
Settle on an SLO – what is the reasonable about of latency, failures etc. Once you have an SLO for the happy path, instrument the happy path in your instrumentation (for instance in Stackdriver)
5. Where are my secrets?
Passwords, PII etc. Secrets can end up in all sorts of places like in logs, in development environments. How can these be managed, can this be centralised so access can be revoked easily.
6. How fault tolerant am I?
Things will go wrong and it may not be your fault, you have to accept faults will happen.
Work backwards to monitoring. Alerts must be actionable and alerts need to work. Use dashboards for critical paths and for holistic views. Design a disaster recovery document and test it.
Valentin then ran through the different compute options and that Stackdriver can be used for monitoring. He wrapped up his portion of the presentation by reviewing some of the features of Stackdriver.
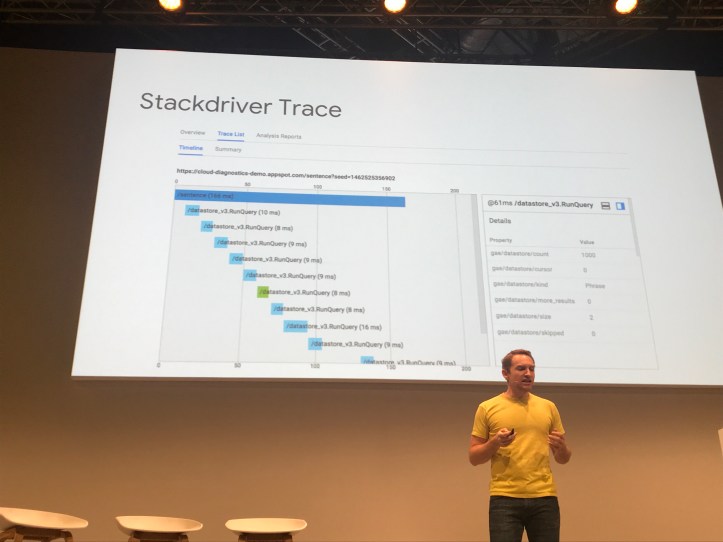
Stackdriver showing a ‘latency waterfall’.
Stackdriver can allow for Live Production debugging, by plugging into the source code and then re-running production events.
Stackdriver Incident Response and Management (IRM), is a new capability of Stackdriver, based on SRE learnings and tooling within Google.
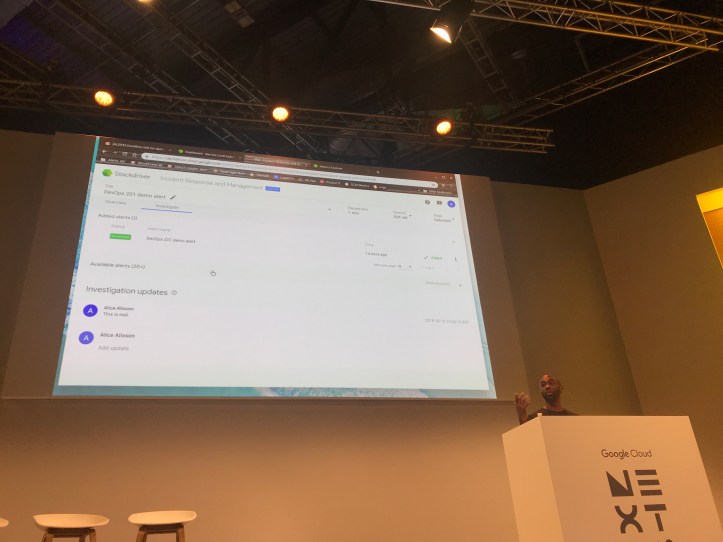
Andre moves on to a live demo of the alpha version of IRM. IRM is integrating monitoring and insights from Stackdriver with a central incident management site where responders can take actions and provide updates on an incident.
Stackdriver IRM also helps with escalations and standardising notifications for when something is escalated. It also helps assign standard SRE roles for an incident, such as Incident Commander, Communications lead etc.
Tags can be added to show the cause and action being taken with the incident.
Future capabilities will be to provide this as part of GKE on prem, and to add post mortem capabilities.
